Le gâteau de l'abstraction
Are you the kind of developer that feels perpetually lost in a codebase? Do you struggle to figure out where and how to make changes? Is every day like cutting into a 100 layer surprise cake where only madness spills out? You’re missing out on abstraction layers. Little slices of comfort that you can stand on and pretend only one problem exists. Building confidence your abstractions will help you better reason through your code and the systems you interact with.

Building and Rebuilding your senses through data
Grant Achatz is a world class chef with four Michelin stars across his Alinea Group restauraunts in Chicago. In 2007 he was treated for tongue cancer and lost all sense of taste. In 2011 he talked with Terry Gross:
I started from zero and the first thing back was sweet. So my palate developed just as a newborn, but I was 32 years old. So I could understand how flavors were coming back and how they synergized together.
Imagine losing all your footing for how you approach problems. You can feel completely blind and disoriented. It’s critical to have anchors that you can rebuild from. I tend to lean on investigating what is in the database to understand the truth of a codebase. There are so many small details you can rebuild to understand what must be happening in the code because the database tells you so.
Take the time to build habits to query the database directly instead of relying on a prod console. If you know how to query something in your ORM it is absolutely worth the time to understand the abstraction layer that was built between your code and the actual database you’re working in. If you’re a sucker for the terminal and using Postgres pgcli is a fantastic tool (mycli for mysql).
ORM to SQL
If you’re trying to figure out how to write raw SQL there are two main tools that I’d recommend. Your ORM will almost always have an explain function. In ActiveRecord (built into Rails and the source of most Rails Magic®) you simply tack on a .explain to the end of your query function. Rails 7.1 exposed even more powerful options to help you go from Ruby to raw SQL. Django has a very similar QuerySet.explain() method. ChatGPT is incredibly good at building and re-writing complex queries. Having confidence to use data to prove what is happening is great for both digging into a codebase and as a way to manage scope.

If you imagine a specific edge case, query the database to understand the magnitude of that problem. Developers love to play “what if” for big scary edge cases. If the surface area is zero for your case, build in an exception and move on it is not a case that matters for your business! If there are less than 1% of total cases, backfill the data then add the exception. If there are over 100 it’s likely you need to talk to product because the missed a persona! Why an exception? When someone starts doing that exceptional thing, future you can look at that PR, remember how dumb (or smart you were) and decide to refactor all with the warm fuzzy confidence that the data is safe!
Simple to say, hard to do
Lets look at an example (and pretend we have this data in the database). Say we have a people table with a full_name column that is an open ended string input with zero validation. We want to start sending emails that are addressed to just that user’s first_name. Should be really simple right? How many people put in Mr. or Dr. or Sir? Do we even know if we can decompose these strings?
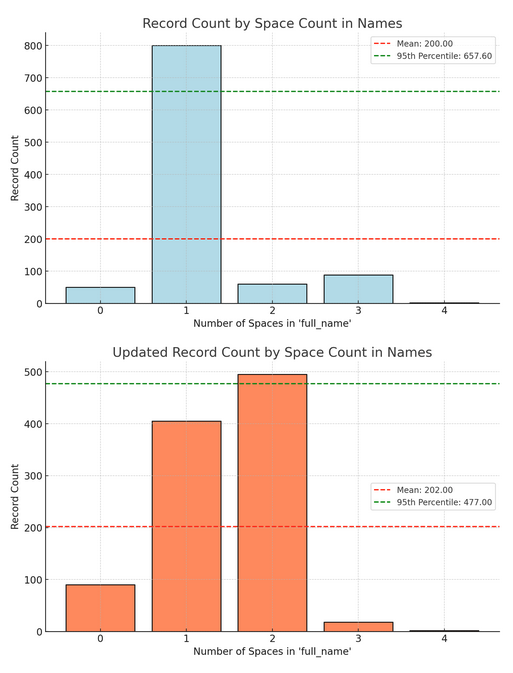
First, lets figure out the surface area of the problem. How many records do we have in total, what are the minimum, maximum, average, and 95th percentile (p95) of spaces. Why percentiles? They help you understand what is the most likely case you’ll have to deal with. If your average (mean) and 95th percentile are very close together that means your data is mostly clustered together in some part of your full range (min..max). If your min or max is far way from both the average and p95 then you have some interesting outlier data that might be better suited for normalization instead of explicitly handling. The graphs are toy examples to help build an intuitive sense of what the could be. Lets look at the raw numbers:
SELECT
COUNT(*) AS total_records,
MIN(len) AS min_spaces,
MAX(len) AS max_spaces,
AVG(len) AS avg_spaces,
PERCENTILE_CONT(0.95) WITHIN GROUP (ORDER BY len) AS percentile_95th_spaces
FROM
(SELECT -- this sub query gives us a basic temp table with all the records as the names with numbers of spaces instead of the full string
LENGTH(full_name) - LENGTH(REPLACE(full_name, ' ', '')) AS len
FROM
people) AS subquery;
| total_records | min_spaces | max_spaces | avg_spaces | percentile_95th_spaces |
|---|---|---|---|---|
| 1000 | 0 | 4 | 1.75 | 3 |
As a first pass this lets us know that there’s data with more than one space which is a pain for this feature. Now we need to understand how big of a pain is that difference going to be?
SELECT
space_count,
COUNT(*) AS records_count,
MIN(full_name) AS sample_record
FROM (
SELECT
full_name,
LENGTH(full_name) - LENGTH(REPLACE(full_name, ' ', '')) AS space_count
FROM
people
WHERE
LENGTH(full_name) - LENGTH(REPLACE(full_name, ' ', '')) BETWEEN 0 AND 4
) AS subquery
GROUP BY
space_count
ORDER BY
space_count;
| space_count | records_count | sample_record |
|---|---|---|
| 0 | 50 | Massimo |
| 1 | 800 | Grant Achatz |
| 2 | 60 | Magnus Nilsson Fäviken |
| 3 | 88 | Albert Adrià El Bulli |
| 4 | 2 | Charles Michel Marie Le Fevre |

Armed with this information you quickly realize that splitting names is going to be a painful long term problem, your first implementation for emails will probably be ok but you should dig into this data for more cases! You also now have specific tests cases to power your implementation if you must. As an IC or a manager this is data that I actively look at to understand how painful a refactor is going to be for myself or my team. Getting ahead of these kinds of problems avoids thrash from even happening because you’re meeting your data where it already is!